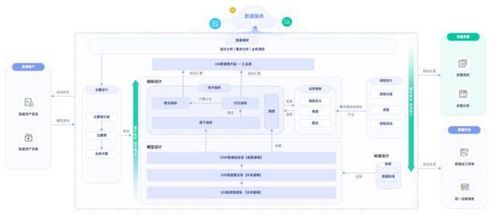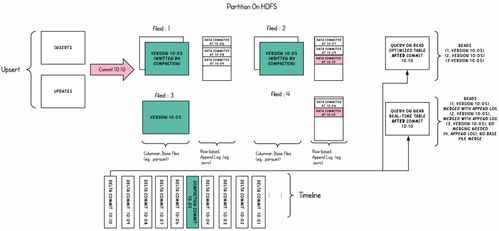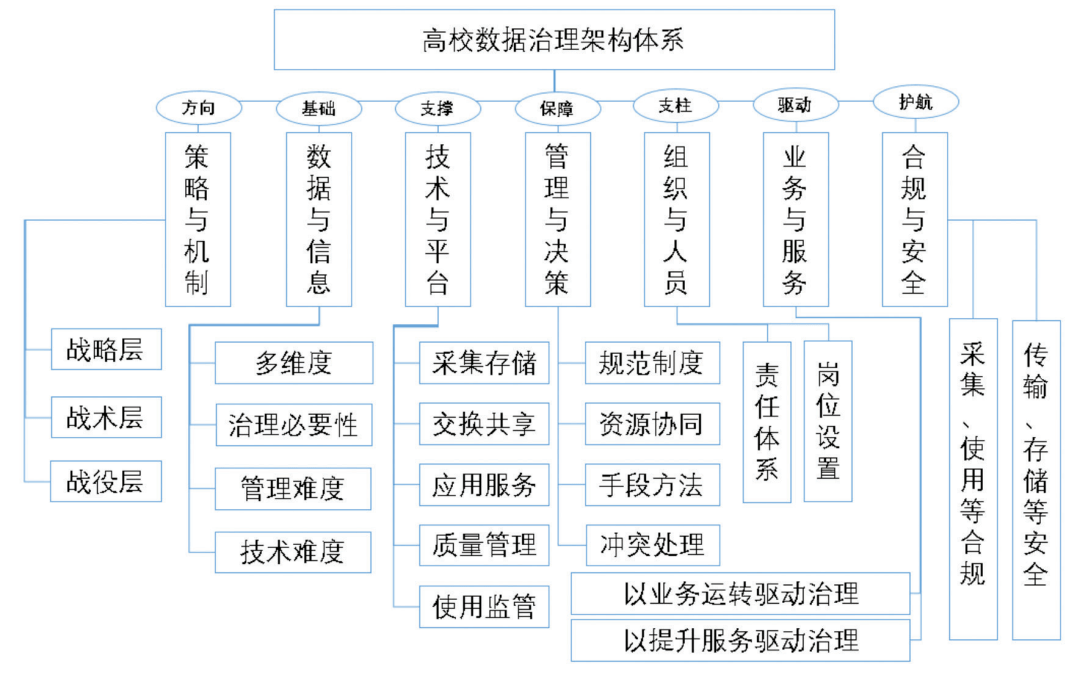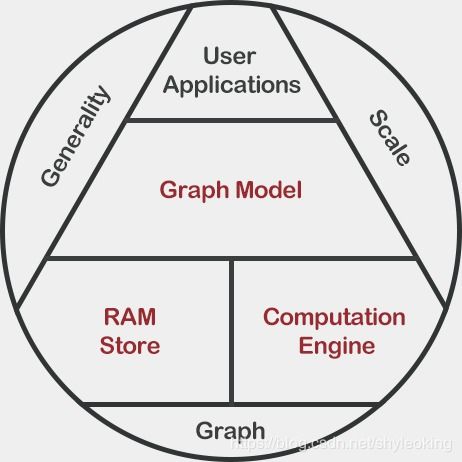
在當今數據爆炸的時代,圖結構數據因其能直觀表示實體間復雜關系,在社交網絡分析、推薦系統、金融風控和知識圖譜等領域得到廣泛應用。為應對海量圖數據帶來的計算與存儲挑戰,Graphengine應運而生,其核心目標是打造一個高性能、可擴展的分布式圖處理引擎,并構建完善的數據處理與存儲支持服務體系,為用戶提供一站式圖計算解決方案。
核心目標一:分布式圖處理引擎
Graphengine的首要設計目標是構建一個強大、靈活的分布式圖處理引擎。傳統單機圖計算框架在處理十億級乃至萬億級頂點和邊的超大規模圖時,常受限于內存、計算資源和網絡帶寬。Graphengine通過分布式架構,將圖數據分區并存儲于多臺機器上,利用并行計算能力同時處理多個子圖任務,顯著提升了處理速度與規模上限。
該引擎支持多種圖計算模型,包括以頂點為中心的編程模型(如Pregel)、以邊為中心的模型以及基于矩陣運算的模型,兼容廣度優先搜索(BFS)、最短路徑(Shortest Path)、社區發現(Community Detection)和PageRank等經典圖算法。引擎內置容錯機制,確保在節點故障時任務能自動恢復,保障了長時間、大規模作業的穩定性與可靠性。
核心目標二:數據處理支持服務
圖數據的價值不僅在于靜態存儲,更在于動態分析與實時處理。Graphengine提供全面的數據處理支持服務,涵蓋數據攝取、清洗、轉換和集成等環節。它支持從多種數據源(如關系數據庫、NoSQL數據庫、流數據平臺及文件系統)導入數據,并轉換為統一的圖模型。通過內置的ETL工具,用戶能定義復雜的數據轉換規則,將原始數據映射為頂點、邊及其屬性,快速構建圖數據集。
Graphengine強調對實時圖處理的支持,能夠對接流式數據源,持續更新圖結構并觸發增量計算。例如,在社交網絡中實時捕捉用戶互動,動態調整推薦策略;或在欺詐檢測中即時分析交易鏈路,識別可疑模式。這種流批一體的處理能力,使得Graphengine既能應對歷史數據的深度挖掘,也能滿足實時場景的敏捷響應。
核心目標三:存儲支持服務
高效的圖存儲是圖計算性能的基石。Graphengine設計了一套分布式圖存儲系統,針對圖數據的特性進行優化。它采用混合存儲策略,將圖結構(拓撲信息)與屬性數據分離存儲,前者常駐內存或高速存儲以實現快速遍歷,后者可持久化至分布式文件系統或對象存儲,平衡性能與成本。
存儲服務支持多種圖數據模型,包括屬性圖、RDF圖等,并提供豐富的查詢接口,如Gremlin或Cypher查詢語言,使用戶能以聲明式方式執行復雜圖遍歷。系統還具備數據壓縮、索引自動構建和數據版本管理功能,提升存儲效率與查詢速度。通過橫向擴展存儲節點,Graphengine能線性增長存儲容量與吞吐量,適應不斷增長的數據規模。
整合與生態構建
Graphengine并非孤立系統,它致力于與現有大數據生態無縫集成。例如,可與Hadoop、Spark等計算框架協同,利用YARN或Kubernetes進行資源調度;也可將計算結果導出至數據倉庫或可視化工具,形成從數據到洞察的閉環。通過提供標準API和SDK,Graphengine降低了開發門檻,使數據工程師和科學家能專注于業務邏輯,而非底層基礎設施。
應用前景與挑戰
隨著圖技術的普及,Graphengine的目標正逐步實現,在金融、電信、醫療和智能安防等領域展現出巨大潛力。分布式圖處理仍面臨挑戰,如數據分區帶來的通信開銷、動態圖的高效更新以及多租戶環境下的資源隔離等。Graphengine需持續優化算法與架構,引入機器學習增強的圖分析能力,并強化安全與隱私保護機制,以鞏固其作為下一代數據基礎設施的核心地位。
Graphengine以分布式圖處理引擎為核心,輔以全面的數據處理與存儲支持服務,旨在破解大規模圖計算的瓶頸,賦能企業挖掘數據關聯價值,驅動智能化決策與創新。