在當今全球化和數字化的經濟背景下,產業鏈的高效、穩定運行至關重要。產業鏈中存在的堵點和斷點問題,如供應鏈中斷、信息不對稱、產能瓶頸等,嚴重制約了整體效能與韌性。為精準識別、預測并疏通這些關鍵節點,大數據分析技術成為核心工具。而這一切的基礎,在于強大、可靠的數據處理與存儲支持服務。本解決方案旨在構建一套專為產業鏈堵點斷點分析而設計的數據基石。
一、 核心挑戰與需求
產業鏈數據具有來源廣、類型雜、體量大、時效性要求高的特點。來自生產、物流、銷售、金融、政策等多維度的數據,包括結構化數據(如ERP、SCM系統數據)、半結構化數據(如XML/JSON格式的訂單、報關單)和非結構化數據(如行業報告、新聞輿情、傳感器日志、圖像視頻),構成了分析的原材料。如何高效地采集、清洗、整合并存儲這些海量異構數據,是精準分析的首要挑戰。
二、 數據處理支持服務:從原始數據到分析就緒
- 多源異構數據采集與接入:
- 服務內容:提供API接口、數據庫直連、文件傳輸、網絡爬蟲(遵守合規與倫理)、物聯網(IoT)設備接入等多種方式,無縫對接企業內部系統(ERP, CRM, MES)、外部平臺(電商、物流追蹤平臺)、公開數據庫及物聯網傳感器網絡。
- 技術實現:采用分布式消息隊列(如Kafka, Pulsar)作為數據總線,實現高吞吐、低延遲的實時數據流接入。
- 數據清洗與標準化:
- 服務內容:對原始數據進行去重、糾錯、補全、格式轉換。針對產業鏈關鍵實體(如企業、產品、地理位置)進行識別、消歧與統一編碼,建立全鏈條一致的“數據身份證”。
- 技術實現:利用基于規則和機器學習的數據質量框架,結合領域知識圖譜,自動化執行清洗任務,確保數據的一致性與可信度。
- 數據融合與關聯:
- 服務內容:將來自不同源頭、描述同一業務對象(如一個零部件從生產到裝配的全過程)的數據進行關聯與整合,構建跨越企業邊界的產業鏈全景視圖。
- 技術實現:通過實體解析、關系挖掘和圖計算技術,構建動態的“產業鏈數字孿生”數據模型,清晰呈現上下游企業、產品、物流、資金流和信息流之間的復雜網絡關系。
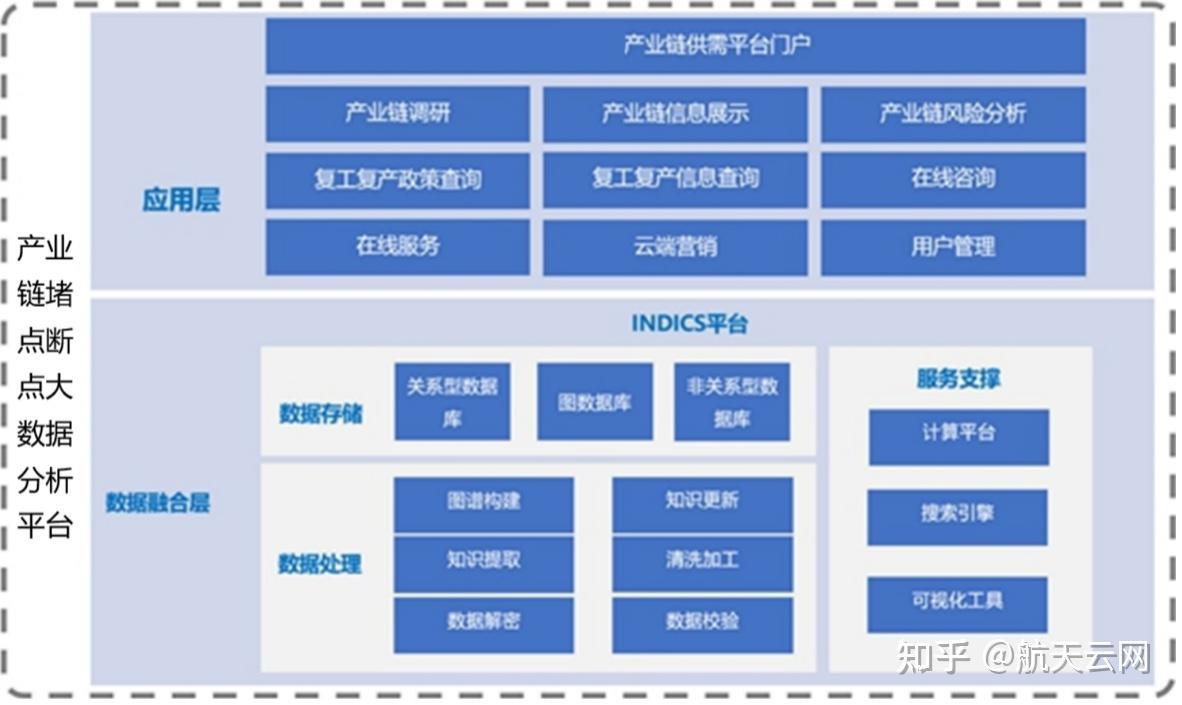
三、 數據存儲支持服務:彈性、智能的存儲底座
- 分層存儲架構:
- 熱數據層(實時分析):采用高性能的分布式內存數據庫(如Redis)或時序數據庫(如InfluxDB),存儲近期的實時交易數據、傳感器數據,支撐毫秒級響應的堵點預警(如某物流節點突然停滯)。
- 溫數據層(交互式分析):利用分布式數據倉庫(如ClickHouse, Greenplum)或大規模并行處理(MPP)數據庫,存儲清洗整合后的歷史明細數據,支持復雜的即席查詢和多維分析,用于定位斷點根源。
- 冷數據層(長期歸檔與挖掘):將海量歷史數據、文檔、音視頻資料存儲于低成本、高可靠的對象存儲(如Amazon S3, 阿里云OSS)或HDFS中,供長期的趨勢分析、模型訓練和合規審計使用。
- 數據湖與數據倉庫結合:
- 建立企業級數據湖,作為原始數據的集中存儲池,保留數據的原始形態,提供最大的靈活性。根據分析主題(如供應鏈風險、產能利用率),從數據湖中抽取、轉換、加載(ETL/ELT)數據到專業的數據倉庫或數據集市中,形成高性能、易用的分析模型。
- 彈性擴展與高可用保障:
- 存儲服務基于云原生架構,可根據數據量的增長和應用負載的變化,實現計算與存儲資源的秒級彈性伸縮。通過多副本、跨可用區部署等技術,確保數據持久性不低于99.999%,服務可用性不低于99.9%,為7x24小時不間斷的產業鏈監控提供堅實保障。
四、 服務價值與產出
通過本數據處理與存儲支持服務,客戶將獲得:
- 統一可信的數據資產:形成覆蓋產業鏈全環節的、高質量、標準化的單一事實來源。
- 實時與批處理一體化的能力:既能對突發堵點進行秒級感知與響應,也能對深層次、周期性的斷點問題進行深度挖掘。
- 靈活高效的分析基礎:為上層的大數據分析應用(如風險預警模型、供應鏈優化仿真、韌性評估指數)提供穩定、高性能的數據供給。
- 成本優化:通過合理的數據分層與生命周期管理,在滿足性能需求的有效控制總體存儲與計算成本。
###
數據處理與存儲支持服務是產業鏈堵點斷點大數據分析解決方案的“地基”。只有構建起堅實、智能、彈性的數據基礎設施,才能讓數據真正流動起來,轉化為洞察力與決策力,最終實現產業鏈的暢通無阻、韌性增強與價值提升。